Mastering AI in Project Management: A Guide to Effective Execution, avoiding common
pitfalls.
Gavin Oh, Managing Partner at Global Business Management Consultants.

Managing Artificial Intelligence (AI) and Machine Learning (ML) projects requires a fundamental shift in mindset. Unlike traditional software development, which is highly deterministic and rule-based, AI is inherently experimental and probabilistic. For Project Management practitioners, this means adapting traditional Agile or Waterfall methodologies to accommodate data dependencies, ongoing model training, and shifting accuracy metrics.
Here is a comprehensive guide on the uniqueness of AI projects, how to prevent common pitfalls, and practical examples to help you deliver AI projects successfully.
A. The Uniqueness of AI Projects
AI projects break the mould of traditional IT projects in several distinct ways:
1. Probabilistic vs Deterministic: Traditional software executes exact rules (if X, then Y). AI predicts outcomes based on patterns (if X, there is an 85% chance of Y). PMs must manage stakeholder expectations around “acceptable error rates” rather than demanding perfection.
2. Data is the True Dependency: In software, your blocker might be a missing API. In AI, your blocker is usually poor, biased, or insufficient data. You cannot build a model without the right fuel.
3. The “Done” Illusion: An AI project is rarely “finished” at deployment. Models degrade over time as real-world data changes (a phenomenon called model drift), requiring continuous monitoring and retraining.
4. Highly Experimental: You often don’t know if the project is feasible until the data scientists explore the data. High iteration and frequent pivoting are standard.
B. The AI Project Process Flow
While standard software uses SDLC, AI projects typically follow a lifecycle closer to CRISP-DM (CrossIndustry Standard Process for Data Mining). Here is a simplified visual flow:
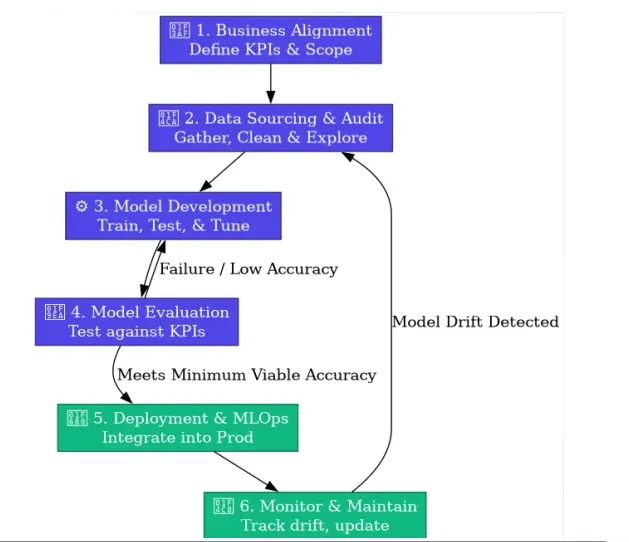
1. Business Alignment
Defining clear KPIs and project scope ensures the ML project aligns with measurable business outcomes.
2. Data Sourcing and Audit
Collecting, cleaning, and exploring raw data lays the foundation for high-quality model development.
3. Model Development
Training, testing, and tuning models iteratively optimize performance while preventing overfitting.
4. Model Evaluation and Deployment
AI projects fail less from “bad models” and more from poor framing, weak data, and delivery unrealistic expectations. Here PM-focused is a practical guide with examples you can reuse in planning and stakeholder conversations. The best prevention is strong scope control, early validation, and clear success criteria. Here are the most critical pitfalls every PM should know, with practical prevention strategies and real-world examples.
C. Common Pitfalls and How to Prevent Them
1. Poor Problem Definition
Pitfall: Starting with *”Let’s use AI”* instead of a clear business problem.
o Why it hurts: Teams build something technically interesting that solves nothing meaningful.
o Prevention: Define the business decision the AI will support, the user, the workflow, and the expected value. Confirm AI is actually the right tool.
o Example:
Bad: “Build an AI chatbot.”
Better: “Reduce level-1 support tickets by 30% for password resets, order status, and FAQ queries.”
2. Low-Quality or Insufficient Data (Garbage In, Garbage Out)
o Pitfall: Jumping into model development before checking whether data is complete, clean, labelled, and representative.
o Why it hurts: The model learns noise, gaps, or meaningless patterns — then confidently makes terrible predictions.
o Prevention: Run a data audit early. Allocate 60–70% of the project timeline to data engineering and exploratory data analysis. Use a Data Readiness Sign-off gate before any modelling begins.
o Example:
A customer churn model looked promising, but 40% of customer activity logs were missing.
The model was learning from unreliable signals.
Prevention: The PM paused modeling, fixed data instrumentation, backfilled where possible, and restarted with a validated dataset.
3. Biased Training Data
o Pitfall: Using historical data that reflects past human bias or skewed processes.
o Why it hurts: The AI reproduces and scales unfair decisions — creating legal, ethical, and reputational risk.
o Prevention: Review sensitive variables and proxy features. Involve legal, compliance, and domain experts. Test model outputs across different user groups before release.
o Example:
A hiring AI trained on past recruitment data consistently favoured male candidates — because historical hiring patterns were biased.
Prevention: The PM halted modelling, removed biased signals, rebalanced the dataset, anonymized inputs and added a fairness review step before any release.
4. Unrealistic Stakeholder Expectations
o Pitfall: Promising near-perfect accuracy or positioning AI as fully autonomous too early.
o Why it hurts: Trust collapses the moment the model makes a normal, expected error.
o Prevention: Align on acceptable performance thresholds early. Explain trade-offs (precision vs. recall). Position early releases as decision support, not replacement.
o Example:
A fraud detection model catches 85% of fraud but flags some legitimate transactions.
Stakeholders expected 100% detection with zero false alarms.
Prevention: Agree upfront that reducing fraud losses by a target percentage is the goal — not achieving perfection. Set clear thresholds for acceptable false positive rates.
5. Choosing the Wrong Success Metric
o Pitfall: Measuring only overall accuracy when the business actually cares about missed risks, false alarms, speed, or cost savings.
o Why it hurts: The team optimizes for the wrong outcome and delivers a model that looks good on paper but fails in practice.
o Prevention: Define technical + business + operational metrics together. Match the metric to the real-world consequence.
o Example:
A medical screening model showed 95% overall accuracy — sounds great. But it missed 40% of actual positive cases (low recall).
In healthcare, missed positives can be life-threatening.
Prevention: Track recall/sensitivity for positive cases as the primary metric, not just overall accuracy. Set separate thresholds for pilot and production.
6. Skipping Feasibility Validation
o Pitfall: Committing to full delivery before proving the use case is technically viable.
o Why it hurts: Teams spend months on projects that were never going to work.
o Prevention: Add a feasibility phase (2–4 weeks). Test with a small, representative dataset.
Define a clear go/no-go checkpoint.
o Example:
o A company wanted AI to auto-classify 20 types of support tickets.
o Early testing showed the existing labels were too inconsistent — humans couldn’t even agree.
o Prevention: Run a feasibility sprint first. The team simplified from 20 categories to 6, improved labelling guidelines, and model performance jumped significantly.
7. Treating AI Like One-Pass Software Delivery
o Pitfall: Building a rigid plan with fixed scope and no room for iteration.
o Why it hurts: AI work naturally loops back through data, features, and evaluation. A rigid timeline breaks.
o Prevention: Plan in phases — feasibility → prototype → pilot → production. Add iteration buffers. Communicate learning milestones, not just delivery deadlines.
o Example:
A recommendation engine underperformed after first training. The PM’s rigid plan had no room to revisit feature engineering.
Prevention: Build in sprint-level review points. The team revisited user segmentation, added behavioural features, and retrained — hitting targets in the third iteration.
8. Weak Stakeholder Involvement
o Pitfall: Leaving domain experts, end users, compliance, or operations teams out until late stages.
o Why it hurts: The model may be technically sound but operationally unusable or unsafe.
o Prevention: Involve business users from day one. Review outputs with domain experts regularly. Include risk/compliance early for regulated use cases.
o Example:
A clinical triage model looked accurate in testing, but doctors found the recommendations too generic and lacking context to act on.
Prevention: Include clinicians in label design, feature review, output format decisions, and pilot testing — not just final sign-off.
9. Ignoring Deployment and Workflow Integration
o Pitfall: Focusing only on model quality and forgetting where and how people will actually use it.
o Why it hurts: Great predictions create zero value if they never reach the right person at the right time.
o Prevention: Design for the actual workflow. Decide how outputs appear — dashboard, alert, API, queue, approval screen. Include change management and user training.
o Example:
o A predictive maintenance model generated useful warnings, but technicians never checked o the analytics dashboard where alerts appeared.
Prevention: Push alerts directly into the maintenance ticketing system they already use daily. Adoption went from near-zero to 80%+ within weeks.
10. No Plan for Monitoring After Launch
o Pitfall: Treating deployment as the finish line.
o Why it hurts: Model performance degrades over time due to data drift, changing user behaviour, or new market conditions — and nobody notices until damage is done.
o Prevention: Define post-launch ownership. Monitor accuracy, drift, latency, and business outcomes. Set retraining triggers and a regular review cadence.
o Example:
A retail demand forecasting model worked well initially, then accuracy dropped sharply after seasonal buying patterns shifted.
Prevention: Add monthly monitoring dashboards, automated drift detection alerts and scheduled retraining cycles before peak demand periods.
11. Poor Governance, Privacy, or Compliance Controls
o Pitfall: Using sensitive data without proper approvals, auditability, or safeguards.
o Why it hurts: This can delay or kill a launch and create serious legal and reputational risk.
o Prevention: Confirm data permissions early. Document data lineage and model decisions. Add human review where required by regulation or risk level.
o Example:
A finance team built a credit-risk model using fields that raised regulatory red flags.
This was only discovered during pre-launch review — causing a 3-month delay
Prevention: Setup proper governance structure involving appropriate expertise to review, audit and approve at major milestones.
AI projects succeed when you start with a clear business problem, invest heavily in data quality, expect iteration, set realistic metrics, plan for deployment adoption, and monitor continuously after launch.
This article was written by Gavin Oh, Managing Partner at Global Business Management Consultants, in collaboration with AI tools. For more information on how GBMC can help you using AI in project write to us at [email protected]






